a=1; b=1
curve(dgamma(x,a,b),0, 10)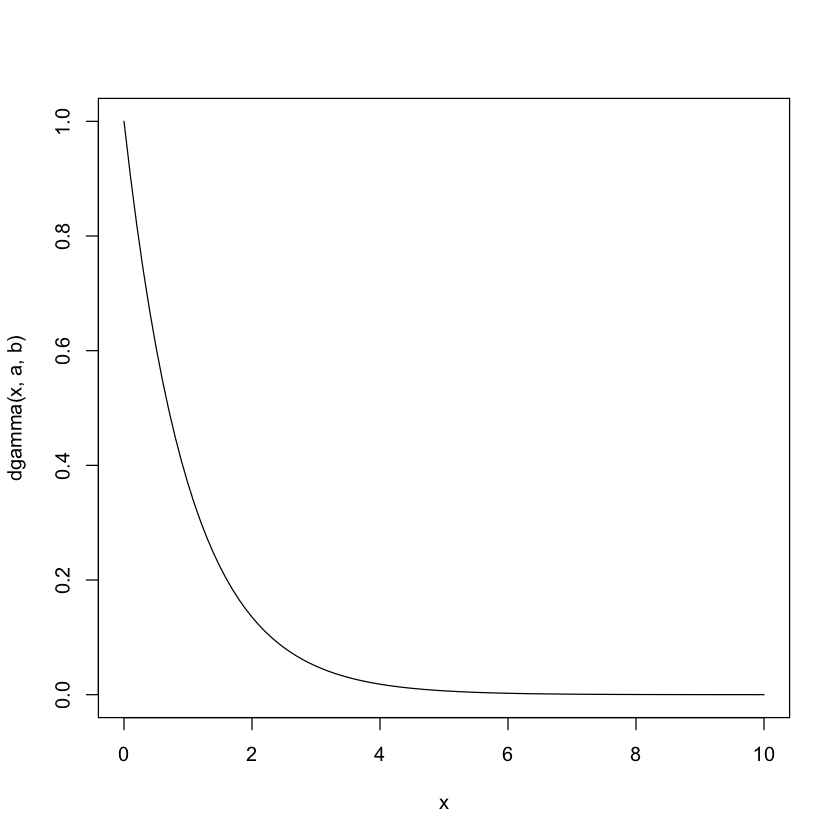
\[p(\theta|y) \propto p(y|\theta)\]
\[\int^{1}_{0}\theta^{a-1}(1-\theta)^{b-1}d\theta = \frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}\]
where \(\Gamma(n) = (n-1)!\).
\[p(\theta) = dbeta(\theta, a, b) = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\theta^{a-1}(1-\theta)^{b-1}\quad \text{for}~0\leq \theta\leq 1\]
If \(Y_{1},\dots,Y_n|\theta\) are i.i.d. binary (\(\theta\)):
\[p(\theta|y_1,\dots,y_n) = \frac{\theta^{\sum y_i}(1-\theta)^{n-\sum y_{i}} \times p(\theta)}{p(y_1,\dots,y_n)} \tag{3.1}\]
If compare the relative probabilities of any two \(\theta\)-values, \(\theta_a\) and \(\theta_b\) (from Equation 3.1):
\[\frac{p(\theta_a|y_1,\dots,y_n)}{p(\theta_b|y_1,\dots,y_n)} = (\frac{\theta_{a}}{\theta_b})^{\sum y_i}(\frac{1-\theta_{a}}{1-\theta_b})^{n - \sum y_i}\frac{p(\theta_a)}{p(\theta_b)} \tag{3.2}\]
Equation 3.2 shows that
\[p(\theta\in A|Y_1=y_1,\dots,Y_n = y_n) = p(\theta \in A|\sum^{n}_{i=1} Y_i=\sum^{n}_{i=1}y_i)\]
\(\sum^{n}_{i=1} Y_i\) is a sufficient statistic for \(\theta\) and \(p(y_1,\dots,y_n|\theta)\). It is sufficient to know \(\sum Y_i\) to make inference about \(\theta\).
In this case where \(Y_1, \dots, Y_n|\theta\) are i.i.d. binary (\(\theta\)) random variables, the sufficient statistics \(Y=\sum^{n}_{i=1} Y_i\) has a binomial distribution with parameters \((n,\theta)\).
A class \(\mathcal{P}\) of prior distribution for \(\theta\) is called conjugate for a sampling model \(p(y|\theta)\) if
\[p(\theta) \in \mathcal{P} \Rightarrow p(\theta|y) \in \mathcal{P}\]
If \(\theta|Y=y \sim beta(a+y, b+n-y)\), then
\[\begin{aligned} E[\theta|y] &=\frac{a+y}{a+b+n}\\ &= \frac{a+b}{a+b+n}\underbrace{\frac{a}{a+b}}_{\text{prior expectation}} + \frac{n}{a+b+n}\underbrace{\frac{y}{n}}_{\text{data average}}\\ \end{aligned} \tag{3.3}\]
From Equation 3.3, the posterior expectation is a weighted average of the prior expectation and the sample average. This leads to interpretation of \(a\) and \(b\) as “prior data”:
The predictive distribution of \(\tilde{Y}\) is the conditional distribution of \(\tilde{Y}\) given \(\{Y_1=y_1,\dots,Y_n=y_n\}\)
\[Pr(\tilde{Y}=1|y_1,\dots,y_n) = E[\theta|y_1,\dots,y_n] = \frac{a+\sum^{n}_{i=1}y_i}{a+b+n}\]
An interval \([l(y), u(y)]\), based on the observed data \(Y=y\), has \(95\%\) Bayesian coverage for \(\theta\) if \[Pr(l(y)<\theta<u(y)|Y=y) = .95 \tag{3.4}\]
A random interval \([l(Y), u(Y)]\) has \(95\%\) frequentist coverage for \(\theta\) if, before the data are gathered,
\[Pr(l(Y) < \theta < u(Y)|\theta) = .95 \tag{3.5}\]
\[p(Y=y|\theta) = dbinom(y,n,\theta) = {n\choose y}\theta^{y}(1-\theta)^{n-y},\quad y\in\{0,1,\dots, n\}\]
\[Pr(Y=y|\theta) = \theta^{y}\frac{e^{-\theta}}{y!}\quad \text{for} y\in \{0,1,2,\dots\}\]
Let \(Y_1,\dots,Y_n\) as i.i.d. Poisson with mean \(\theta\), then the joint pdf is
\[\begin{aligned} Pr(Y_1 =y_1,\dots, Y_n = y_n |\theta) &= \prod^{n}_{i=1} p(y_i|\theta)\\ &= \prod^{n}_{i=1} \frac{1}{y_{i}!} \theta^{y_i}e^{-\theta}\\ &= c(y_1, \dots, y_n)\theta^{\sum y_i}e^{-n\theta} \end{aligned}\]{#eq-pois-son}
Let \(\bar{Y}\) be a data point that is yet to be observed.
\[\begin{aligned} p(\bar{y}|y) &= \int_{\Theta} p(\bar{y}, \theta|y)d\theta\\ &= \int_{\Theta} p(\bar{y}|\theta,y)p(\theta|y)d\theta \end{aligned}\]Comparing two values of \(\theta\) a poseteriori,
\[\frac{p(\theta_a|y_1,\dots,y_n)}{p(\theta_b|y_1,\dots,y_n)} = \frac{e^{-n\theta_a}}{-n\theta_b}\frac{\theta_{a}^{\sum y_i}}{\theta_{b}^{\sum y_i}}\frac{p(\theta_a)}{p(\theta_b)}\]
\[p(\theta|y_1,\dots,y_n) \propto p(\theta) \times \underbrace{p(y_1,\dots,y_n|\theta)}_{\theta^{\sum y_i} e^{-n\theta}}\]
\[p(\theta) = \frac{b^a}{\Gamma(a)}\theta^{a-1}e^{-b\theta} \quad \text{for } \theta, a, b > 0\]
\[\int^{\infty}_{0} \theta^{a-1}e^{-b\theta}d\theta = \frac{\Gamma(a)}{b^a}\]
Conjuagate prior of Poisson data
\[p(\theta) = \frac{b^a}{\Gamma(a)}\theta^{a-1} e^{-b\theta}I_{0,\infty}(\theta)\]
\[E(\theta|y) = \frac{a+n\bar{y}}{b+n} = \frac{b}{b+n}\frac{a}{b} + \frac{n}{b+n}\frac{n\bar{y}}{n} = (1-\omega_n)E(\theta) + \omega_n \bar{y}\]
a=1; b=1
curve(dgamma(x,a,b),0, 10)
a=4; b=4
curve(dgamma(x,a,b),0, 10)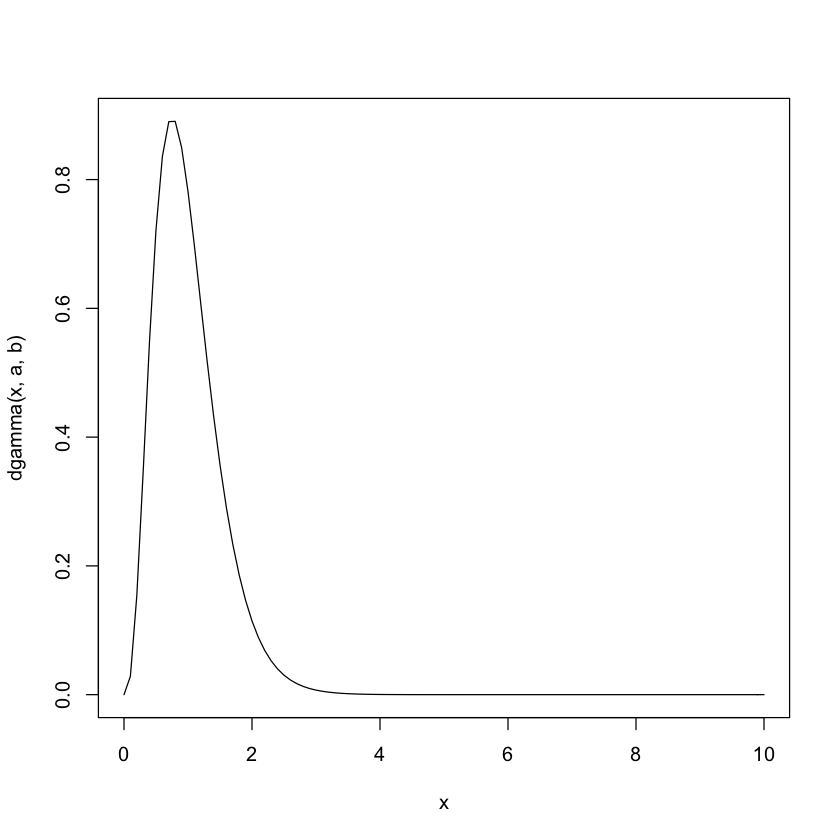
a=16; b=4
curve(dgamma(x,a,b),0, 10)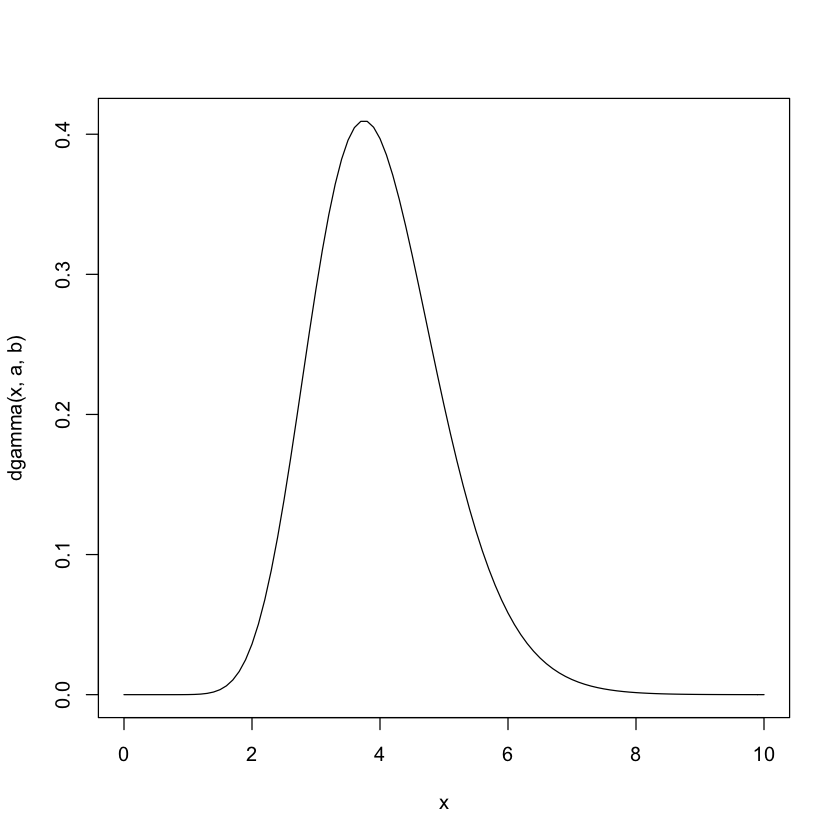
\[\begin{align} p(\phi|y_1,\dots, y_n) &\propto p(\phi)p(y_1,\dots,y_n|\phi)\\ &\propto c(\phi)^{n_0 + n} \exp \left(\phi \times \left[ n_0 t_0 + \sum_{i=1}^{n}t(y_i) \right]\right)\\ &\propto p(\phi|n_0 +n, n_0t_0 +n \bar{t}(y)) \end{align}\]
where \(\bar{t}(y)=\frac{\sum t(y_i)}{n}\)
http://www.mas.ncl.ac.uk/~nmf16/teaching/mas3301/week11.pdf
R installation: https://www.drdataking.com/post/how-to-add-existing-r-to-jupyter-notebook/